|
Analysis of Inventory and Accounting
See also:
Using the
Accounting Models
A large proportion of commercial computing systems are designed to track the
money moving through an enterprise, recording how it is earned and spent.
The fundamental idea behind accounting and inventory tracking is that there are
various pots of money and goods, and we must record how money and goods
move among these pots.
The inventory and accounting patterns in this analysis are born from this
fundamental idea. They present a core set of concepts that we can use as the
basis
for financial accounting, inventory, or resource management. The patterns do not
describe these processes directly, rather they describe the underlying ideas
from
which processes can be built. Discussion in
Using the
Accounting Models describes a simple example that uses
these ideas for billing telephone calls.
In this analysis we use a simple personal financial example to explain the basic
ideas of accounting and inventory. Although similar, the terms we use are not the
terms traditionally used in financial accounting. In our search for a more
abstract
model, we found that we needed new terms and concepts. A particular feature of the
patterns in this analysis is how the rules for processing are embedded into the
accounts system. This approach allows the accounts to update and manage
themselves. This turns a traditionally passive recording system into an active
system that can be configured by wiring up the accounts in the appropriate
manner.
The first pattern is that of an Account (Section 1). An account holds things of
value - goods or money - which can only be added or removed by entries.
The entries provide a history of all changes to the account. When we use an account
to record the history of changes to a value, it is important to check that items do not get lost.
Transactions (Section 2) add a further degree of auditability by linking
entries
together. In a transaction, the items withdrawn from one account
must be
deposited in another; items cannot be created or destroyed.
There are two kinds of transactions: A two -legged transaction moves an
amount from one account to another. A multi-legged transaction can have entries
in several accounts as long as the transaction as a whole balances.
Accounts can be grouped together using a Summary Account (Section 3), which
applies most of account's reporting behavior to groups of accounts.
Sometimes
we need to make account entries that are not designed to be kept in balance; a
Memo Account (Section 4) deals with this task.
An account can include fixed rules that govern how amounts are transferred
between accounts. Posting Rules (Section 5) allow us to build active networks of
accounts that update each other and reflect business rules. To achieve this,
instances of a posting rule require their own executable methods, a requirement
that introduces the important modeling concept of an Individual Instance Method
(Section 6). Individual instance methods can be implemented with some
combination
of a single sub-type, the strategy pattern, an internal case statement, an
interpreter,
and a parameterized method.
The Posting Rule Execution (Section 7) pattern describes ways in which posting
rules can be triggered: while a transaction is created; by asking an account to
process its rules; by asking a posting rule to fire; or by asking an account to
bring
itself up to date, thus firing its predecessors in a backward chaining manner.
To use posting rules with many accounts, we need a way of defining Posting
Rules for Many Accounts (Section 8). One way is to use a knowledge level, in which
case
posting rules are defined on account types. Another way is to link posting rules
to
summary accounts.
In an accounting system, various objects will want subsets of the account's
entries and their balances, both of which require a pattern for choosing entries
(Section 9). This pattern is useful whenever we want a selection of objects from a
multi-valued mapping. Our alternatives are to return the whole set and let the
client do the selection, adding extra operations to the account, or using an
account
filter.
We can divide large networks of posting rules into groups by using the Accounting
Practice (Section 10) pattern. In long calculations we often need to go
back
to see why various transactions gave the result they did; then we need to use
the
sources of an Entry (Section 11) pattern.
Balance sheets and Income Statements (Section 12) distinguish between accounts
that record items being held and accounts that record where items
come or go.
Different people can have similar views of accounts; for example, our view of
our
bank account is probably similar to our bank's view.
One is a Corresponding Account (Section 13) of the other.
The resulting patterns are quite abstract; particular cases need a Specialized
Account Model (Section 14) to apply them to everyday practice.
Such accounts are
developed by sub-typing the general accounting patterns.
The final pattern in this analysis describes booking entries to Multiple Accounts
(Section 15). This pattern is useful when there is more than one way of
reporting the
trail
of entries. The two alternative techniques are using memo entries or using
derived
accounts. We can use derived accounts instead of
accounting patterns when we
want the reporting behavior of accounts but not the balancing and audit
capabilities.
These models are the results of ideas generated during several projects. They
originated from working on a customer service system for a US utility company,
and were further developed while examining accounting structures for an
international telecommunications company. The models also draw deeply from
the recent development of a payroll system for a major US manufacturing
company.
Key Concepts: Account, Transaction, Entry, Posting Rule
1. Account
In many fields it is important to keep a record of not only the current value of
something but also details of each change that effects that value. A bank
account
needs to record every withdrawal and deposit; an inventory record needs to
record each time items are added or removed.
An account is similar to a quantity attribute, with an added entry for every
change to its value, as shown in Figure 1. The balance, which represents the
current value of the account, is the net effect of all entries linked to the
account.
This does not mean that the balance needs to be recalculated each time it is
asked
for. Derived values can be cached, although the cache would be invisible to the
account user. By using the entries, a client can also determine the changes over
a
period of time and the total amount of deposits or withdrawals (see Section
9).
The sign on the amount indicates whether the entry is a deposit or a withdrawal.
A statement is a list of all the entries that have been carried out against an
account
over a period of time.
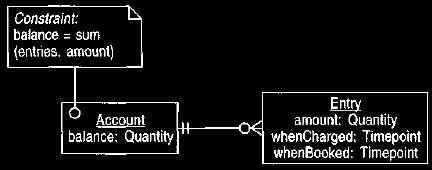
Figure 1. Account and entry.
The entries record each change to the account.
Example: we withdraw $100 from our checking account. This is represented as an
entry with
amount -$100 attached to our checking account.
Example: we buy 4 reams of standard letter paper from a shop. The shop represents
this as an
entry on their standard letter paper account with amount -4 reams.
Example: In January we use 350 KWH of electricity. This is represented as an entry
with
amount 350 KWH to our domestic electricity usage account.
Modeling Principle: To record a history of changes to a value use an account for
that value.
One way an implementation can compute a balance is to take a collection of
entries and form a collection of quantities. Smalltalk has a specific operation,
collect, to do this. The danger is that the collect operation collects the
objects into
the same kind of collection as the original. Thus running collect on a set of
entries
yields a set of quantities. Sets allow no duplicates, so if we have two entries
with
the same amount, only the first entry's quantity is counted, and the balance
value is
incorrect. To form collections of fundamental values, it is often better to use
a bag,
which does allow duplicates. In C++ this problem is less common because collect
operations are less common and more difficult to use; instead C++ users use an
external iterator which does not have this problem. As a check, however,
test
cases should always include entries with equal amounts (as well as entries with
every attribute equal).
Figure 1 indicates two timepoints for the entry: one indicates when the
charge is made and the other when the entry is booked to the account. This is
particularly important when retroactive charges occur. A price for a charge may
have changed between the charge date and the booked date, so both dates are
required. We need to know both the history of events and our knowledge of that
history. Timepoints also include both the time of day as
well
as the date;
many applications are happy with just the date.
Example: we have a meal at Jae's Cafe on April 1. The credit card company receives
notice of
payment on April 4. The entry has a charged date of April 1 and a booked date of
April 4.
2. Transactions
Using entries help keep a record of changes to an account. These changes usually
involve moving an item from one account to another. When we withdraw money
from our bank account, we am adding money to our wallet, or cash account. With
many items it is not enough to just record the comings and goings; we must also
record where they come from and go to.
The transaction helps by explicitly linking a withdrawal from one account
to a deposit in another, as shown in Figure 2. The double entry
approach reflects a
very basic accounting principle that money (or anything else
we must account for) is never created or destroyed, it merely moves from one
account to another.
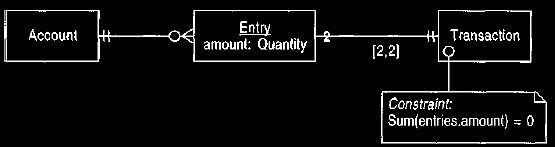
Figure 2 A transaction with two entries.
Example: we use our credit card to pay Boston Airlines $500 for an airline ticket.
This is a
transaction from the credit card account to the Boston Airlines
account with an
amount of
$500. Later we will make a transaction from our checking account to the credit
card account to
bring the credit card
account's balance to zero.
Example: Aroma Coffee Makers (ACM) moves 5 tons of Arabian Mocha from New York to
Boston. This is transaction from the New York account to the Boston
account with
an
amount of 5 tons.
In complex accounting structures we aim to get the accounts to balance— that
is, to reach zero—at various points in the business cycle. By building the
principle
of conservation into the model, we make it easier to find any "leaks" in the
system. Although it's not essential to use transactions when you are using
accounts,
we
prefer to.
Modeling Principle: When working with accounts, follow the principle of
conservation: The
item being accounted for cannot be created or destroyed,
only moved from place
to place.
This makes it easier to find and avoid leaks.
2.1 Multi-legged Transactions
Figure 2 implies that each transaction consists of a single withdrawal and a
single corresponding deposit. In fact we can have many withdrawals and deposits
in a transaction. Say we receive $3000 from Megabank and $2000 from Total
Telecommunications. we decide to deposit both checks into our checking account.
Our bank statement will show a $5000 credit. Note that although two checks have
hit our bank account, a single entry is shown. This transaction is represented by
the multi-legged transaction model shown in Figure 3. The upper bound on the
mapping is lifted from transaction to entry. The overriding rule is that the
entries
must balance with respect to the whole transaction, but no match is required
among individual entries. Thus we can model our bank account situation with a
transaction that consists of three entries: [account:
checking account, amount: $5000], [account: Megabank, amount: ($3000)],
[account: Total Telecommunications,
amount: ($2000)]. The transaction is
responsible for ensuring that money is not created or destroyed.
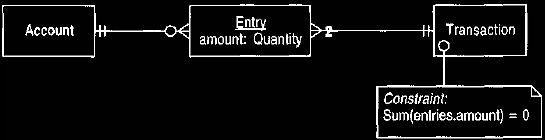
Figure 3 Multi-legged transactions.
These allow more flexibility in forming transactions than the two-legged model.
Example: Aroma Coffee Makers removes 5 tons of Java from New York and sends 2
tons to
Boston and 3 tons to Washington. This is a single transaction
with three
entries: [account:
New York, -5 tons], [account: Boston, 2 tons], [account: Washington, 3 tons].
The two-legged model is a particular case of the multi-legged model where the
transaction has only two entries. In some applications the two-legged model
predominates, and we have a model similar to Figure 4. Other applications
might have a large number of multi-legged transactions. we would recommend the
multi-legged approach because it provides more flexibility. Two -legged
transactions can easily be created by a special creation operation on a
multi-legged
transaction, which is a useful convenience. The rest of this discussion assumes
the
multi-legged model.
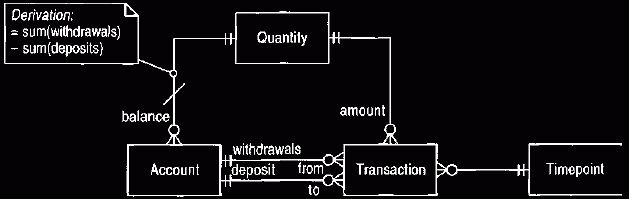
Figure 4 A model of a two-legged transaction that does not use entries.
This model may be found where all the transactions are two-legged. It has much
the same
capabilities as Figure 2. However, we would prefer using Figure 2 since
it is
easier to
migrate to a multi-legged transaction.
The mutual mandatory relationship between transaction and entry introduces
a chicken and egg problem. we cannot create an entry without creating a
transaction
because of a constraint. Similarly we can't create a transaction without an entry
because transaction is similarly constrained.
One solution is to provide a creation operation on transaction that takes a list
of partially defined entries, or even a list of arrays with appropriate
arguments.
Entry would have its creation operation made private but accessible to the
transaction's creation. The transaction's creation would then be the only place
that
could create entries. Obviously, during the execution of this creation
operation,
objects would be in violation of their constraints. The rule with constraints,
however, is that public operations should end with all constraints satisfied.
Providing only the transaction's creation routine is made public, this rule can
be
enforced.
3. Summary Account
In a system of accounts it is often useful to group accounts together. For
example, we might want to group our Total Telecommunications and Megabank accounts into
a business income account. Similarly we want to put rent and food into personal
expenses and our business travel and office expenses into business expenses. This
kind of structure can be supported with a simple hierarchy of detail and summary
accounts, as shown in Figure 5.
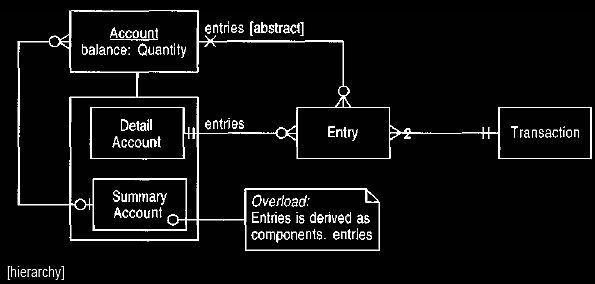
Figure 5 Summary and detail accounts.
A summary account can be composed of both summary and detail accounts. This
forms
a hierarchy, with the detail accounts as leaves (an example of Composite).
The
entries of a summary account are derived from the components' entries in a
recursive
manner.
In this hierarchy structure we can bring together accounts into summary
accounts. We restrict the system to posting entries only to detail accounts and
not
to summary accounts. Summary accounts can still be treated as accounts because
their entries are derived according to their components' entries. A summary
account that contains summary accounts will look for entries in its components,
its
components' components, and so on, recursively. This derivation of the entries
mapping allows us to describe the balance attribute, and any other operations
and
attributes that depend on entries, at the super-type level.
Example: we have a summary account for air travel with detail accounts for
Mega-bank air
travel and Total Telecommunications air travel.
Example: Aroma Coffee Makers has a summary account for Java with detail accounts
for
each warehouse. It can thus find out the total amount of Java that it owns.
Note that the relationship among components needs to be marked to show it
is a hierarchy. The cardinalities are not enough to enforce this constraint. We
must not have cycles in this structure.
The separation between summary and detail accounts is quite common in
accounting, but it is not absolutely necessary. The model in Figure 6 shows
the
distinction removed. In this case an entry can be made to any account, and all
accounts can be placed in a hierarchical structure. This can be done by
providing
two mappings from account to entry: one to show which entries are posted at that
level, and another to add together the entries on sub-accounts. The first would
be
updatable, the latter is derived, not updatable, and used for balance,
statements,
and other features that were on the super-type in the Figure 5 model.
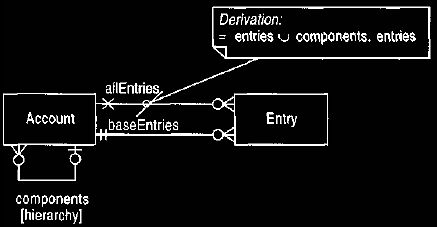
Figure 6. Account hierarchies without separating summary and detail accounts.
We
can use this model to post entries to summary accounts.
So far we have followed conventions that say that accounts must be arranged
in a hierarchy and that entries are booked to only one account. We will continue
with these assumptions for a while, but we will consider some alternative
possibilities later on in Section 15.
4. Memo Account
Benjamin Franklin once said, "In this world nothing can be said to be certain,
except death and taxes." We can't eliminate the pain of paying taxes, but
we find
the
pain is lessened somewhat by avoiding surprises on our tax return. Each time we
earn some money, we allocate a portion to a tax liability account. we then know
how
much of our money is really mine, and how much we owe in taxes.
Notice that with this plan, no real money has moved. There is no payment
from our checking account until we have to pay the tax. Furthermore, our tax
category lumps together state and federal taxes. When we actually pay (and when
we
pay estimates], we will make transactions from our checking account to the
accounts federal tax and state tax. When we do this we need to reduce our tax
liability
account by the same amounts, but again no money moves between the real
accounts (checking account, federal tax, state tax) and this tax liability
account.
This account acts as a memo to us on how much money we owe in taxes, thus it is
referred to as a memo account.
A memo account contains amounts of money but not real money. It is
important that no real money leaks from or to a memo account. So in our tax
example, as we take the money from our income account to our checking account we
make an entry at the same time into our tax liability memo account. Memo
account becomes another sub-type of account, and we have to ensure that
transactions do not shift money between that and the other accounts. This can be
done by ensuring that the balance constraint on transaction excludes memo
accounts.
If we are using transactions, we need to ensure that we always move money
between accounts and that we do not create or destroy money. This implies that
when an entry is made to the tax liability account, a balancing entry is made
somewhere. Since it can be difficult to see what account would be a sensible
host
to this entry, accountants frequently create a contra account. Thus the tax
liability
account would have a contra tax liability account, which acts as the other end
of all
entries in the tax liability account, either withdrawals or deposits. This
approach
can be used with the usual model, but it is not strictly necessary. If the
balance
checking constraint ignores memo accounts, then single-sided entries against
them are allowed. A contra account can always be generated automatically. This
approach would imply that the lower bound on the mapping from transaction to
entry can be reduced to 1.
Example: Each time we receive a payment from a client, we record it as a
transaction from a
client income account to our checking account. We also enter a portion
of that
amount into the
tax liability memo account. When the time comes to pay estimated taxes, we make a
transaction from our checking account to our
federal tax account. We add a third
entry to this
transaction to reduce the amount on our tax liability memo account by the same
amount.
Of course, if we don't use transactions, we don't run into any balance
problems and can post the entries without worry, but the danger is that real
money can leak into memo accounts (or into thin air) more easily.
5. Posting Rules
Using a memo account we can make a posting to a tax liability account, but we
still
have to remember to do it. Since we always enter 45 percent of each fee income
entry into a memo tax liability account, a computer system should be able to do
it
for us automatically.
What is needed is a rule that looks at a particular account and, when it sees an
entry, creates another entry. A simple example of this kind of rule is shown in
Figure 7. A posting rule is described by specifying an account as a trigger.
Any
entry in the trigger account causes a new entry to be made, which is the value
of
the original entry multiplied by the multiplier.
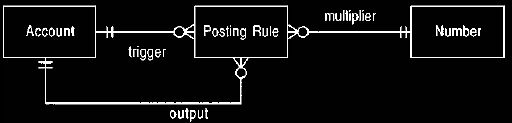
Figure 7 A simple structure for posting rules that multiply by a factor.
For each entry in the trigger account, we post an entry to the output account of
the value
of the triggering entry multiplied by the multiplier.
Example: Our tax liability can be handled by a posting rule with the fee income
account as
the trigger, the tax liability account as the output and the multiplier as 0.45.
Multiplication by a scalar handles a number of useful situations for a posting
rule, but the process can easily get complex. Consider a graduated income tax:
The first £300 carries no tax, the next £2500 carries a 20 percent tax, the rest
is at
40 percent. A simple scalar multiplier is no longer enough. We want posting
rules
to carry any arbitrary algorithm, which would give us the maximum flexibility.
To give posting rules this flexibility, we have to link a calculation to each
instance of a posting rule, since every rule will have a different way of
calculating
the amount of the new entry. Conceptually this means that each instance of a
posting rule needs to have its own method for doing the calculation, as shown in
Figure 8. The glib notation masks a significant problem. Mainstream object
systems allow behavior to vary by polymorphism and inheritance, but this is
class
based: The behavior varies with the object's class. We want the behavior to vary
with each individual instance, which requires the individual instance methods
pattern, as discussed in Section 6. (We discuss a similar problem in
Analysis of Exchange Trading, Section 2.)

Figure 8 Posting rules with methods to calculate values for entries.
This notation says that each instance of a posting rule has its own calculation
method.
5.1 Reversibility
An important property of posting rules is that they must be reversible. Usually
we
cannot delete an incorrect entry because either it has led to an entry that is
part of a
payment or it appears on a bill. The only way we can remove its effects is by
entering a reversal, which is an identical but opposite entry. Thus any posting
rule
must ensure that two entries that are identical but of opposite signs are both
placed
in the trigger account and completely cancel each other out in further
processing.
We can test the reversal by inserting such opposite pairs in routines for a
posting
rule and ensuring their output amounts are also equal and opposite.
5.2 Abandoning Transactions
In some accounts almost all transactions are generated from posting rules. Input
accounts are used to record initial entries from the outside world. All further
account entries are generated by posting rules. The risk of not using
transactions is
reduced because all entries are predictable from the initial entries and the
posting
rules. The responsibility to check that nothing leaks out is transferred from
the
operational use of the system to the design of the posting rules. If we remove
transactions, then it is still valuable to keep a note of the cause and effect
trail
between entries. On the whole we prefer keeping transactions because they make
auditing easier for a small price in overhead. If you don't use transactions,
you
will still need some audit mechanism.
6. Individual Instance Method
A conceptual model should represent a situation as naturally as possible for the
convenience of the domain expert. We should minimize dependencies on a
particular implementation environment as much as possible. Computer design
should reflect human thinking, not the other way round. This philosophy is
reflected in the diagram shown in Figure 8. After defining this conceptual
modeling construct, we need to invent a general way of implementing it. Hence
the question is not "How do we put calculations on individual posting rules?"
but
"How do we attach methods to instances?" This follows the transformational
approach. We want several ways of implementing the
model in Figure 9 behind a single interface. This follows the overriding
principle of template-based design.
The model should define the interface of the
classes. We should be able to exchange the implementations without altering the
interface.
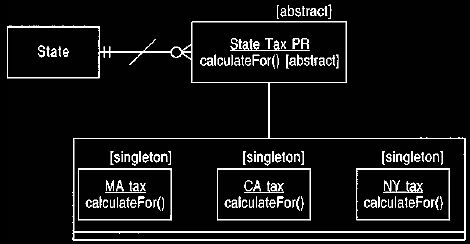
Figure 9 Using singleton classes to implement individual instance methods.
6.1 Implementation with a Singleton Class
The natural way to vary behavior is to use a polymorphic operation based on
subclassing. The simplest way to do this is to subclass the posting rule for
each
instance of the posting rule, thus creating a number of singleton classes. Here
all
the standard methods and properties for posting rules are held by the posting
rule,
and the sub-types merely implement the different CalculateFor methods.
The main problem with this approach is that the sub-types are rather artificial.
They only exist because of the fact we cannot vary CalculateValue by instance.
This artificiality makes the approach less than perfect. Another problem is that
this approach leads to many classes, which makes some people feel rather
uncomfortable. Classes do not present a particularly large
problem because the classes are both small and very constrained. Calculation
methods can be sharedby manipulating the class hierarchy. However, the process
operation on the posting rule can also be the victim of polymorphism, and the
two
polymorphisms
may not match.
6.2 Implementation with the Strategy Pattern
On first sight the Strategy pattern implementation shown in
Figure 10
looks very similar to the pattern using singletons. The main difference is that
Figure 10 performs sub-typing on a separate method, or strategy, object. The
posting rule is simpler because the whole issue of method choice is eliminated.
The posting rule just knows it can ask a method object to do the calculation.
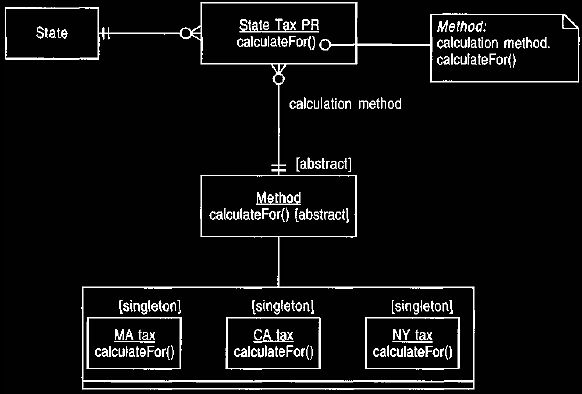
Figure 10 Using the strategy pattern [1] implementation for individual
instance
methods.
Figure 11 shows the interactions that occur in an example case. An account
asks a process rule to process it. The process rule gets all the entries that
have not
been processed by this rule (see Section 7.2). For each of these entries, it
calls
its method to calculate the value of the new entry. The method may need to ask
questions; for example, tax rates often vary depending on whether a person is
married or not. It passes the result back to the posting rule, which then
creates the
new entry.
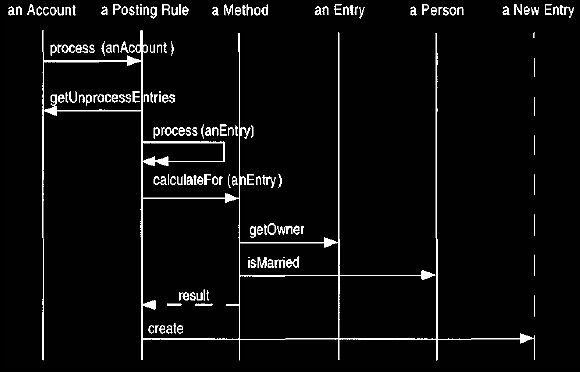
Figure 11 Interaction diagram for using the strategy pattern.
The method gets any information it needs by asking the supplied entry.
It should be stressed that this method object is not a "free subroutine," in the
manner of functional designs (or some OO approaches). The method is
encapsulated within the posting rule, since only the posting rule can reference
and
use it.
Posting rule methods can be shared between objects. An example of such a
method is the flat tax method, which applies a flat rate of tax with some
standard
deductions. If the method is the same for several kinds of taxes, with only the
rate
of tax varying, then a method can be designed that asks the posting rule for its
flat
rate but otherwise allows the processing to be reused. This method can be seen
as
a cross between the method object and the parameterized method (see Section
6.4) implementations.
A variation on this approach in Smalltalk is to use a block as the method. By
doing this we eliminate the need for a new method class and eliminate the method
class' subclasses. Blocks are elegant to use but can be very tricky to debug: If
an
error occurs in the block's code, it can be difficult to follow what is going
on. If the
block is simple, however, this approach can work very well.
6.3 Implementation with an Internal Case Statement
Faced with creating subclasses just to handle one polymorphic method, we might
wonder why we should bother. Instead we can have a series of private operations
for the posting rule: ComputeFederalTax, ComputeMassTax,
ComputeSalesCommision, and so on. Then a single ComputeFor on the posting rule
has a simple case statement that chooses which private method to use depending
on which instance is the receiver, as shown in Figure 12.

Figure 12 Using an internal case statement for an individual instance method.
This is not a violation of object-oriented principles as long as the case
statement is
encapsulated within the posting rule.
Object designers tend to recoil at the idea of using case statements like this,
but in this situation there is a lot to be said for it. Modifying this
implementation
means adding a new private operation and adding a clause to a case statement.
This is not much different from the new subclasses required with the strategy or
singleton implementation. If the number of methods is large, then we have a
large
(but simple) case statement, or a large number of subclasses. Thus it is a
trade-off
between managing a lot of singleton classes and having to change the case
statement with each new posting rule.
6.4 Implementation with a Parameterized Method
The parameterized method strategy uses a single method in the posting rule and
handles the different behavior by using conditions based on properties of the
posting rule, or of related classes. For example, if all the entries are a flat
percentage, then the posting rule can hold the percentage, and a single method
that
deducts that percentage is sufficient, as shown in Figure 13.
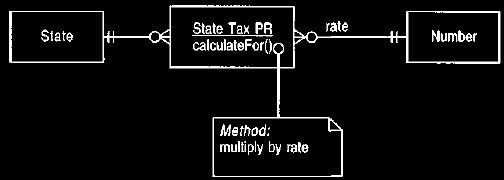
Figure 13 Using a parameterized posting rule.
If some posting
rules have different percentages for married and single people,
then a married and single rate can be held in the posting rule, and the method
asks
the employee for marital status and then uses the appropriate rate.
This strategy works if all the variations in the calculation can be captured by
varying a few parameters. In such cases, however, we must model it that way.
Individual instance methods are only present if the situation is more
complicated
than that. This is a potential implementation because in some cases we can
combine parameterization with another technique.
6.5 Implementation with an Interpreter
If the method is simple, then we can hold the method as a string in a simple
language and build an interpreter for it. Each instance of the method holds its
particular string and the method class can interpret the string (perhaps using
the Interpreter pattern).
Good candidates for this implementation are methods that use simple formulas
that use the arithmetic operators, parentheses, and a couple of simple
functions. If
the language is simple, it is not too difficult to build the interpreter. The
only
limitation is what can be expressed in the language.
6.6 Choosing an Implementation
All of the implementations work well and can be hidden behind a single
operation. We use a parameterized method if we can. Our next choice is to use the
parameterized method implementation in conjunction with one of the other
patterns to see if we can find a blend that uses only a few variant methods to
handle
the larger variations and many parameters to handle the smaller variations. If
only
a few variant methods are needed, then either singletons or an internal case
statement works well. If there are many variants, then the strategy pattern is
the
best. On the whole the strategy pattern is never much worse than singletons or
internal case statements, but it may be a little bit more difficult to
understand at
first sight. If the method can be expressed with a simple language, such as an
arithmetic formula, then the interpreter is a good idea. As the "Gang of Four"
patterns become more widespread, a combination of the strategy pattern and a
parameterized method will become the dominant choice.
All four of the above strategies show ways in which the problem of individual
instance methods can be handled. We can say that the model shown in Figure 8
is the analysis statement of specification, and the designers can choose
whichever strategy is the best for the implementation conditions. This works as
long as a common interface exists for each strategy. The principle of one
analysis
model defining a single interface that can be implemented in many ways is the
foundation of the approach of using design templates for development.
Many modelers would prefer another way of modeling the problem than that
shown in Figure 8. They might prefer an expression closer to one of the other
strategies. They can still make the separation of analysis from implementation
if
they substitute another implementation behind the same interface. Other
modelers would prefer to model in the same form as the implementation. In this
situation they are trading off implementation independence for a greater
seamlessness between analysis model and implementation.
This illustrates clearly the difficulty in drawing a line between analysis and
design. Just as various combinations of classes may satisfy a particular
interface
in software, we may use different combinations of types to model the same
situation in conceptual models. The choice of types can influence the choice of
classes. The overriding influence is that the choice of types defines the
interface
of classes, but what lies behind that interface need not match the conceptual
picture.
7. Posting Rule Execution
So far we have looked at how a posting rule is structured and how it responds to
being fired, that is, told to execute. This is a good point to step back and
look at
some of the strategies we can use to fire posting rules. The first point we want
to
stress is that posting rules should be designed in such a way that they can be
fired
by different approaches. It is important to separate the strategy of firing the
posting rules from the rules themselves as much as possible to reduce the
coupling
between these mechanisms.
7.1 Eager Firing
In this approach posting rules are fired as soon as a suitable entry is made in
a
trigger account. There are two ways we can do this. One is to put the
responsibility in the transaction or entry creation methods, as shown in Figure
14. Creating a transaction leads to several entries being posted to accounts.
Each posting of an entry prompts a search for posting rules that are using that
account as a trigger. Each of these posting rules is then fired.
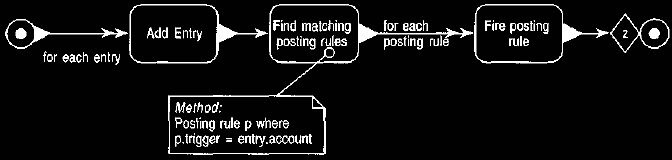
Figure 14 Event diagram showing how transaction creation can trigger posting
rules.
The finding and firing of posting rules can be done either during transaction
creation or in the individual entry creation methods, as shown in Figure 15.
The
latter is a better factoring of the process.
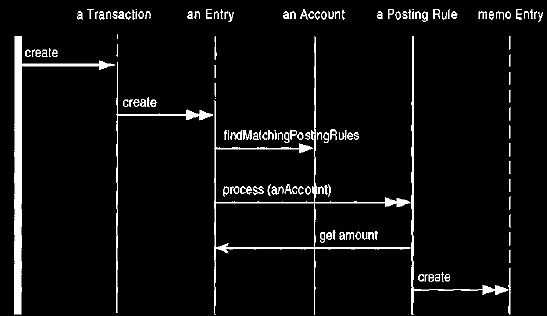
Figure 15. Interaction diagram for firing posting rules within entry creation.
A second approach is to make posting rules observers of their trigger account. When a posting rule is set up, it registers itself to the trigger account.
When an
entry is attached to an account, the account broadcasts to all observers that a
noteworthy event has occurred. The posting rule then interrogates the account to
find out what has happened and discovers the new entry. It then generates the
appropriate new entry to the memo account. The advantage of this scheme is that
the transaction no longer needs to activate the posting rule. The observer is a
very
useful mechanism, but we tend to use it only when there is a need to ensure that
visibilities run solely from the observer to the observed, particularly when
they lie
in different packages. We don't like to use observers when we don't need to,
because
too many of them make debugging difficult. We don't think we would put the posting
rules in a separate package so there is no need to use the observer.
7.2 Account-based Firing
Account-based firing moves the responsibility of firing from transactions to the
account. Entries can be added to an account without any posting rules being
fired.
At some point the account is told to process itself and then fires its outbound
posting rules for all entries that have arrived since the last time it processed
itself,
as shown in Figure 16.
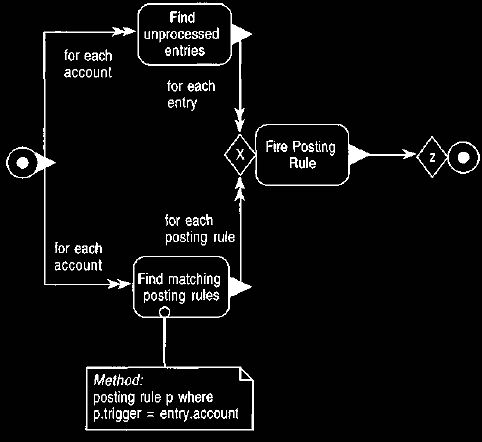
Figure 16. Cyclic firing of accounts.
The X notation indicates that the fire posting rule operation is executed for
each
combination of posting rule and unprocessed entry.
Account-based firing requires the account to keep track of which entries have
not been processed yet. It can do this by maintaining a separate collection for
unprocessed entries (keeping its entries in a list and keeping track of the last
entry
to be processed), or by recording the timepoint of the last process and
returning
entries that were booked after that time (using the when booked property).
Account-based firing can be used in a cyclic accounting system, where
accounts are processed once a day. In this case you must be careful that the
accounts are processed in the right order. Accounts must be processed before any
accounts that may be affected by their outbound process rules. These
dependencies can be determined automatically by looking at the process rules.
7.3 Posting-rule-based Firing
In posting-rule-based firing the posting rule is explicitly told to execute by
some
external agent. It looks at its inputs to find what new entries have appeared.
As
such, posting-rule-based firing is similar to account-based firing,
with many of the same advantages and disadvantages. The main difference is that
since an account can have many posting rules, the responsibility for deciding
which entries have not been processed passes from the account to the posting
rule.
This usually makes the situation more complicated, so we prefer account-based
firing.
7.4 Backward-chained Firing
Backward-chained firing is a variant on account-based firing: The accounts do
not just process themselves, and they cause all accounts that they are dependent
on to process themselves. With this approach we can discover the up-to-date
status of any account.
We can start this process by asking an account for its entries, as shown in
Figure 17. The account first brings itself up to date. The account uses the
posting rules to determine which accounts are triggers for a posting rule that
has
itself as an output. These accounts are asked to bring themselves up to date,
which is a recursive process, as shown in Figures 18 and 19. The whole
account graph is brought up to date by simply asking an account at the end to be
processed.

Figure 17. Requesting a detail account for its entries with backward-chained
firing.

Figure 18. Method for bringing an account up to date.
The bring account up to date operation is called recursively on each account
that is an input
for the processing account.
7.5 Comparing the Firing Approaches
The primary considerations in choosing a firing approach is the time taken in
executing the posting rule (an implementation decision) and the point at which
we
want to catch errors. Eager firing allows us to get errors as soon as they are
found.
This gives us more time to find the cause of the errors. It does force us to do
all the
calculations when we are making entries. Account-based and backward-chained
firing give us more flexibility in the timing of calculations. If we process
accounts
in a batch method, we can read all the entries from a file and then fire the
posting rules at our leisure, perhaps overnight.
The sooner we fire, the sooner we will find any mistakes.
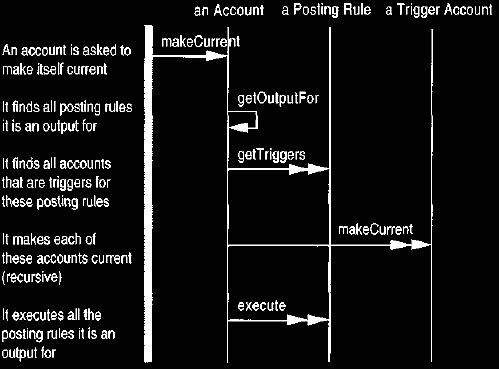
Figure 19. Interaction diagram for bringing an account up to date for
account-based firing.
Choosing between account-based and backward-chained firing is really
about whether we want to handle the extra complexity of building
backward-chained firing. Backward chaining is more awkward to build than
account-based, but once built it is easier to use. Thus we would use
account-based
for simple account structures and backward-chained for complex account
structures. On the whole we don't like eager firing because it is not as
flexible.
We can get all the benefits of eager firing by ensuring that posting rules are
fired as soon as we
add entries (but not as part of entry creation).
Although this is an extra step,
it
does allow us to choose not to do so if we wish. Eager firing does not give us
that
choice. If we have so much processing power
that the posting rules do not cost
anything, then it makes no difference.
There is no reason why you cannot mix the firing approaches. Income
accounts might use eager firing into a couple of layers of asset accounts and
then
use backward chaining for the rest of the way. Using more than one firing scheme
will make the system more complex and confusing, however, so we don't mix them
unless we have a good reason.
This kind of approach is still new, and we are still learning about the
trade-offs inherent in the various firing schemes. Since this is such a fluid
area, it
is important to retain flexibility so that you can change the firing scheme as
you
watch the system in action.
8. Posting Rules for Many Accounts
So far we have considered the parochial example of myself and
our own chart of
accounts. We need to extend this to handle many people. We want the posting
rules to be consistent, so that a single federal tax posting rule can be used to
determine federal tax liability for all the people involved.
With this extension there is no longer a posting rule operating over a single
account. Each employee needs a unique account, yet the federal tax liability
posting rule should be programmed to work for all employees. We do not want to
have to make a separate posting rule for each employee.
There are two ways we can do this. The first is to use the notion of knowledge
and operational levels (see
Analysis of Corporate Structure, Section 5).
We set up the posting rules at the
knowledge level and link them to account types, as shown in Figure 20. Thus we
would have account types for fee income,
pretax earnings, net earnings, and so
on.
Entries that appear in accounts check the posting rules on their account type,
effectively adding a level of indirection
to the kinds of expression discussed
above.
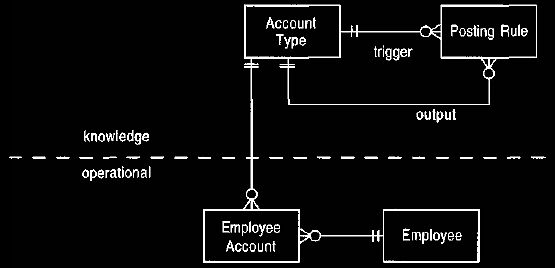
Figure 20. Using account types.
This introduces a knowledge level on which the posting rules can be defined.
Example: All employees accrue 1 day of holiday for every 18 days worked. This
could be
represented as a posting rule with a trigger of the account type days worked and
an output
of the account type accrued holiday. This method ensures that the accrued
holidays account
balance was 1/18 of the days worked balance.
Each time the employee account is
triggered, it
looks for posting rules defined on its account type according to the type of
triggering being
used.
However a knowledge/operational split, although appealing, is not the only
way of handling this situation. A second approach is to use summary
accounts. A posting rule defined on a summary account is activated when any
entry is placed into any subsidiary of the summary account (or the account
itself,
if summary account posting is allowed). The output account can similarly be
defined on a summary account with the interpretation that this will cause an
entry
on the appropriate subsidiary account.
Example: In this case there are summary accounts for days worked and accrued
holiday.
The posting rule is the same as the example above. Instead of checking
the
account type for
posting rules, the summary accounts are checked.
The choice between the two methods depends on the degree of difference
between account and account type. If all posting rules are defined on account
type
and entries are made on accounts, then the knowledge/operational split is
reasonable. However, sometimes this situation does not occur. Entries can be
made at the more general level, perhaps to indicate a general fee to the company
(which would require the model shown in Figure 6). Similarly, posting rules
might vary with each individual payment: This would be required to support
deductions for a car loan, for example. When such situations occur, it is better
not
to make the split.
There is no generally correct approach to take. In any given situation it is
necessary to see which model provides the best fit. The key factor is the degree
of
difference in the behavior of the candidate accounts and account types.
In either case the posting rule needs to determine how to make the correct
output entry. In many of the examples above, the posting rule simply looks for
the
account for the same employee as the triggering entry. More complex situations
are possible, however. Consider a situation where a fee entry to a junior
consultant
causes a percentage of the fee to be posted in a memo account for that
consultant's
manager. In this case the posting rule needs to be told how to find the lucky
manager.
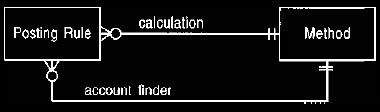
Figure 21. Using an account finding method.
Separate methods are used for finding output accounts and calculating the value
of the
transaction.
One way of handling this is to provide a second method to find the appropriate
output account, as shown in Figure 21. This second method asks the originating
entry for its employee and then that employee for its manager.
This provides the greatest degree of flexibility, at the cost of a second method
object,
which must be implemented as suggested in Section 6.
This hints at another problem. With general posting rules not all employees
may be eligible for the posting rule to fire. For example, posting rules can be
set
up to handle each state tax. A posting rule for Illinois state tax should only
fire,
however, if the employee is a resident of Illinois. Thus suggests a third
method,
which is used to express the eligibility condition, as shown in Figures 22 and
23.
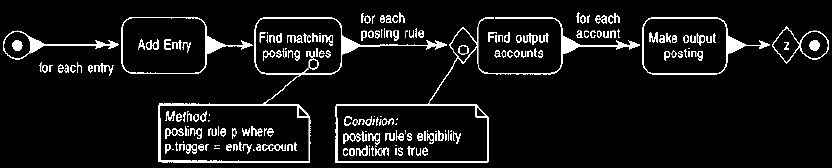
Figure 22. Event diagram showing the use of account finder and eligibility
condition methods added to Figure 14.
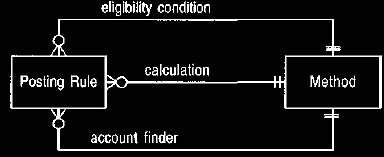
Figure 23. Adding an eligibility condition to the above rules.
In many situations a posting rule needs to select some subset of entries from
its
trigger account. It may want to look at all entries since a certain date booked,
the
balance of all entries charged in July, or entries of dangerous goods (which
would
use some sub-type of entry). There are three ways of performing selections:
getting
all entries back and then doing a selection, providing a selection-specific
method,
and using a filter.
The first technique is the simplest: The account returns all the entries, and
the
client processes this collection to select the entries it needs. This requires
no
additional behavior on the account but passes all responsibility to the client.
If
many clients need to carry out similar selections, a lot of duplication can
occur.
If
there are many entries, there may well be an overhead in
passing the set out, especially if the set needs to be copied. Remember that an account should never
pass out an unprotected reference to its own way of storing
entries (see Section 14.1). Using this approach with entries also means that the
client is responsible for summing the entries to get a balance.
If many clients are asking for a similar kind of selection, such as entries in a
time period, then an additional behavior can be added to the account to satisfy
this (such as EntriesChargedDuring (TimePeriod)). This has the advantage of
saving all the clients from repeatedly going through the same selection process.
We
can save the clients even more effort by providing a method that gives a balance
over a time period (such as BalanceChargedDuring (TimePeriod)). The
problem
with this solution is that if there are many such selections, the
account
interface grows very large.
A filter (see Analysis of Exchange Trading, Section 2) is an object that encapsulates a query. Using that
pattern here would result in an account filter. An account filter
includes
various
operations to set the terms of the query. Once the filter is set up, it is
applied to
the account to get the answer, as shown in Figure 24.
The account uses the
filter to select the subset of entries by conceptually taking each of its
entries and
testing it with the filter's IsIncluded method.
It may apply its private
knowledge
of how the entries are stored to optimize this process. With this approach the
account can support most selections of entries
with EntriesUsing
(AccountFilter) and give corresponding balances with BalanceUsing
(anAccountFilter). Note that if sub-types of entries have additional features
that are
used as a basis for selection, then sub-types of account filter may be needed for
each type of entry.
With a multi-valued association we start by returning all the objects and leave it
up to the client to select them. If there are a few frequently used selections,
we
might consider using an additional behavior, but only for a few behaviors. If a
selection results in too much duplication to return all the objects, but there
are
too many behaviors to add, we set up a filter. Setting up and maintaining a
filter
does require extra work, so we use it only when we really need it. This need often
appears with accounts and their entries.
10. Accounting Practice
When we run into a large network of accounts with many posting rules, the
network becomes too big to deal with. In this situation we need some way to
break down the network into pieces. Consider a utility's billing procedures.
They
bill the various types of customers they have with different billing processes.
This
can be represented as a network of accounts. Each type of customer has different
rules and can be handled with a slightly different network of accounts.
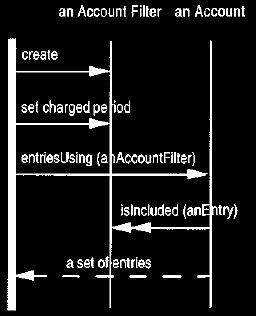
Figure 24. Interaction diagram for using an account filter.
A particular network of accounts is an accounting practice. Conceptually an
accounting practice is simply a collection of posting rules, as shown in Figure
25.
The notion is that each type of customer is assigned an accounting
practice
to handle billing.

Figure 25. Accounting practice.
These are used to group posting rules into logical groups.
Example: A power utility divides its residential customers into regular and
lifeline categories.
The lifeline category is for those who the state deems need
to be charged
minimum rates.
The regular customers are divided into three different rate schedules depending
on the
area in which they live. This is handledby four accounting practices: one for
lifeline and one
for each of the three areas.
Example: ACM has many union workers and each union negotiates a different deal.
ACM
has a pay practice for each union.
The same posting rule can exist in more than one practice. This is often the
case when similar behavior is needed across practices. We need to be aware of
the
difference between copying a rule from one practice (leading to two identical
rules)
and having the same rule in more than one practice. Having a rule in more
than
one
accounting practice implies that when the
rule is changed it changes for all practices that use it. Copies allow one copy
to
change without the others changing.
Accounting practices are assigned to some user object so that each user has a
single accounting practice. Thus each customer of a power utility or employee of
a
company uses a particular accounting practice. This assignment can be done
manually or a rule can determine it.
Example: In ACM the pay practice is assigned to a worker based on his union.
Instead of using an accounting practice, you can use a posting rule that
divides up entries depending on an attribute of the employee. Instead of using
one
practice for each union, you can use only one practice. The first posting rule
looks
at the union of the employee that the entry is made for and makes an entry for
the
appropriate union account (see Section 7.6 for an example of this kind of split
posting rule).
We prefer to use separate practices if the problem is at all complex, providing
that we can assign a practice to a user for a period of time. Any splits that
always
change on an entry-by-entry basis (such as the evening/day split discussed in
Section 7.6) must have a posting rule to handle them. If a user changes its
accounting practice, we can use a historic mapping to keep a
record of these changes.
When different stages of processing have logically separate clumps of
posting rules, we can split the rules up into different practice types and give
a user
a practice from each type. In Figure 26 an accounting practice can have users
that can, in general, be any object. In a particular model, of course, users
would be
customers, employees, or the like. Each user has one accounting practice of each
type, a constraint that is enforced by the keyed mapping.
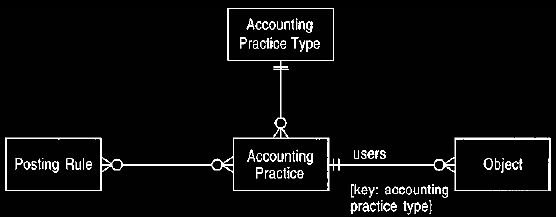
Figure 26. Accounting practice type.
In larger account networks we define a configuration of accounting practices
that vary
for each object that uses them.
Example: A utility has several practices for billing its residential customers,
but all residential
customers are taxed the same way. We can handle this by
having separate charging
and
taxing practices. All residential customers have the same taxing practice,
although they
have separate charging practices.
A logical conclusion to this discussion is to treat accounting practices and
posting rules as parts of the same composite [1]. This allows composition of
practices for many levels. So far we haven't seen a great need for this, so we
have not
explored it further.
11. Sources of an Entry
It is often important to know why a particular entry is in the form it is. For
example,
if a customer calls to ask about a particular entry, the current model
can give
us
quite a lot of information about how the entry was created. We can determine the
state of the account at that time by looking at the dates of
other entries. We
can
also determine which posting rule calculated the entry. The model shown in
Figure 27 can handle such customer requests by getting
each transaction to
remember which posting rule created it and which entries were used as input for
the transaction.(If you are not using transactions, the association runs from
entry
to entry.)
Example: we received $2000 for some work for ACM, which we recorded as a
transaction from
fee income to checking account. Our posting rule created a
separate transaction
into our tax
liability account. The creator of this transaction was the 45 percent posting
rule, and the
sources for this transaction contained
the withdrawal from the fees income
account.
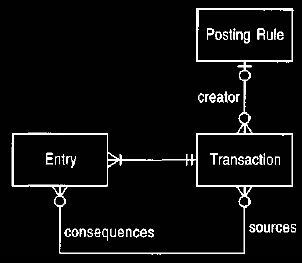
Figure 27. Sources for a transaction.
This records a full trail of calculations for each entry in both directions.
Using this pattern, we can form a chain of entries and transactions across the
accounting structure. Each entry can determine all the causes and effects by
recursive use of the sources and consequences mappings.
Modeling Principle: To know why a calculation came out the way it did, represent
the
result of the calculation as an object that remembers the calculation
that
created it and the
input values used.
12. Balance Sheet and Income Statement
When using accounts to describe a system, it can be worth distinguishing between
the balance sheet and income statement accounts, as shown in Figure 28.
Our
checking account is an asset account, and our credit card account is a liability
account. They reflect the money we have (or in the credit card's case, don't
have)
at
any period of time. These appear on our balance sheet. Income and expense
accounts reflect where money comes from or goes to. We have an income account
for our employer, another income account for interest from our savings, an expense
account for traveling, another for food, and so on. The balances of our income
and
expense accounts do not reflect any money we currently have, merely our
classification of where it comes from and goes to.
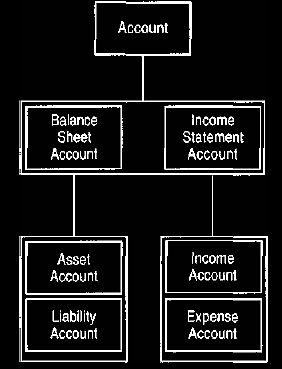
Figure 28 Asset, income, and expense accounts.
These are the kinds of accounts usually found in financial accounting. The
concepts are
useful elsewhere to distinguish between things held and the classification
of
where they
come from and go to.
Accounts are generally used in a pattern where items enter the world via an
income account, pass through several asset accounts, and are disposed of via an
expense account. Any assets that are saved by the system are kept in particular
asset
accounts, but many asset accounts are merely staging places intended
to be
balance
regularly. Liability accounts are almost always intended to balanced at some
point
(which may be far in the future for a long-term debt
such as a mortgage).
Example: we buy a ticket from Boston Airlines with our credit card. Our credit
account is a
liability account, and the Boston Airlines account is an expense account.
Both
accounts are
classified by us, and we are the owner of the credit card account (it is our
liability).
Example: ACM buys 3 tons of Java from Indonesian Coffee Importers. ACM has an
income
account for Indonesian Coffee Importers to record the transfer of the
3 tons of
Java from
Indonesian Coffee Importers to ACM's New York account. The New York account is
an asset
account, owned by ACM.
At this point we can quickly explain why we have avoided the terms debit and
credit. These are well-known terms that apply to accounts, yet we have ignored
them in favor of from, to, deposit, and withdrawal. The reason is that debit and
credit are not used consistently in the sense of deposit and withdrawal. For
income
statement accounts, credits increase an account and debits decrease it, which
makes sense for the layperson. For balance sheet accounts, however, debits
increase assets (that is, they are deposits), and credits decrease assets. This
may
seem strange to non-accountants, but it is the usual accounting convention.
We
have
thus avoided debit and credit, partly because they might confuse any
non-accountant readers, and partly because we are working with a more abstract
model than regular financial accounting.
13. Corresponding Account
Although income and expense accounts are external —the money is not
mine—they are our accounts in that we choose the classification. The bank's view
of accounts illustrates this. We have a checking account that is an asset within
our
personal system of accounts. The bank has an account within its system of
accounts that looks remarkably similar. The bank is the classifier of the bank's
account, but we own the assets within it. We could consider this the same account
as the one in our system of accounts, but this would not work. We might post an
entry for an ATM withdrawal on March 1, which is the day we made the
withdrawal. The bank posts the same withdrawal on March 2 because that is the
next working day at the bank. The two accounts both refer to the same asset, but
they are not the same because their entries differ. It is better practice to
consider
the two accounts as corresponding.
Corresponding accounts are expected to match in some way and are usually
reconciled at some point. This is what happens when we match our checkbook (our
account) against the bank statement (the bank's account). The reconciliation
process may be precise, or it may allow some imprecision, such as slight
differences in dates.
Figure 29 illustrates this situation. Only balance accounts have owners;
income statement accounts do not have assets so there is no question of
ownership.
All accounts have a classifier to indicate who creates and manipulates the
accounts; we have used party (see Section 2.1). The correspondents relationship
shows a couple of special properties: symmetry and transitivity. First it is
symmetric: If account x is a correspondent of account y then account y must be a
correspondent of account x. The usual default for associations is that they are
asymmetric. Transitivity indicates that if account y is a correspondent of
account
x and account z is a correspondent of account y, then account z is a
correspondent
of account x.
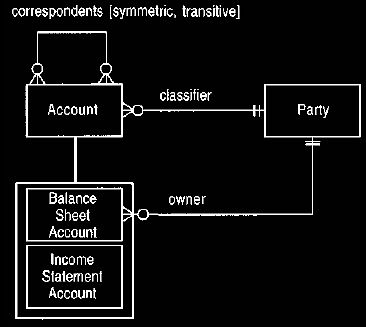
Figure 29. Corresponding accounts.
14. Specialized Account Model
We have provided several examples to show that this model can be used as a basis
for both financial accounting and inventory tracking. With the accounting models
it is usual to sub-type to provide the information for the particular domain. For
example, consider inventory management—a problem suited to the use of
accounts. We can form an account for each combination of kind of goods and
location (and give it a less accounting name, such as holding).
Thus if we are tracking bottles of Macallans, Talisker, and Laphroig whiskey
between London, Paris, and Amsterdam we would have nine holdings (asset
accounts, such as London-Macallans, London-Talisker, Paris-Talisker, and so on).
Whenever we move goods from one location to another, we create a transfer
(transaction) to handle the movement. As with money, transfers have to balance.
In addition, the kind of object must be the same throughout the movement.
Figure 30 shows this kind of extension to the account model.
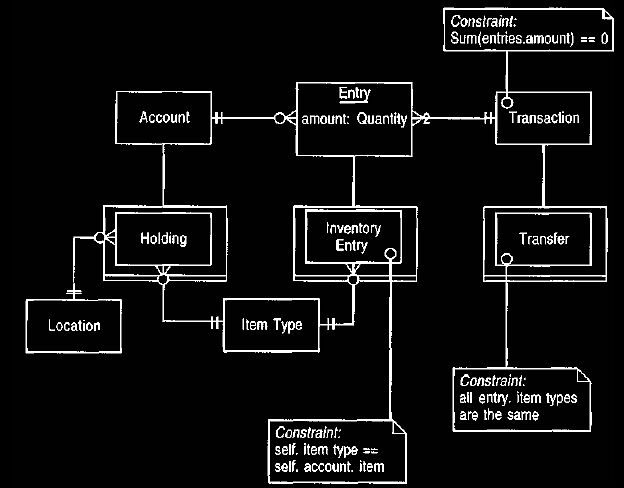
Figure 30. Specializing the account model to support inventories.
This kind of specialization should be done to use the accounting model in a
particular
domain.
This approach could also work to track orders, both incoming and outgoing.
Each supplier would have an income account, perhaps more than one if supplier
location was important. Similarly each customer would get an expense account.
We can track orders in two ways: We could allow sub-types of transfer, either
ordered or actual, or we could provide another set of holdings for orders, so we
would have, for example, London-Talisker-Ordered and London-Talisker-Actual.
When an order is placed, we would make a transfer
from a supplier ordered holding to the ordered holding at the location we want
it
delivered.
When the order is delivered, we would make the transfer between the
ordered holding and the actual holding at our location. This is exactly the same
as using a receivables account in financial books.
We can use summary holdings to get an overall picture. A summary holding
of all ordered holdings can give the total ordered position, and a summary
holding of Talisker gives the total amount of Talisker in all locations.
15. Booking Entries to Multiple Accounts
A common problem in dealing with accounts is when there is more than one place
to book an entry. For example, suppose we paid $500 for our airline ticket
to
attend
the OOPSLA conference. Do we book this to an OOPSLA account (so that we can
work out how much it cost us to attend OOPSLA) or to an air travel
account (so
that we can work out how much we spent on air travel)? There are several ways to
handle this, which illustrate some useful points about using
accounts and also
illustrate more complex account structures than the simple account hierarchies
mentioned earlier.
A typical consultant's bill illustrates the problem. Let's say that we do three
days' consultancy for ACM. We charge them $6000 for the work. In addition, we run
up some expenses: $500 for the air fare, $250 for the hotel, $150 for car
rental,
and $100 for meals. How do we account for this, or more precisely, how do we
account for this if we have a decent accounting system? Clearly we need an account
for ACM so that we can send them a bill. However, one account is not enough.
We are
interested in seeing how much we earn from various clients. When we do this
analysis, we do not want to see the expenses because they are not earned money.
Similarly our tax liability estimates also need to ignore expenses. This indicates that
we
could
use separate accounts for ACM fees and ACM expenses.
Our ACM bill is then
formed by a summary account over these two accounts, as shown in Figure 31.
The problem with this is that we need a separate account for all earned fees.
This
fee account would include accounts for ACM fees, Megabank fees, and
other clients' fees. This also works as a summary account, but it breaks the hierarchical
restriction of Figures 5 and 6. Thus we need to alter the model to allow a
detail
account to have multiple summary accounts as parents, as shown in Figure 32.
The model in Figure 32 allows the accounts to form a directed acyclic
graph. Thus an account can have many parents, but we avoid cycles (an account
cannot be its own grandparent). This structure allows multiple summary
accounts.
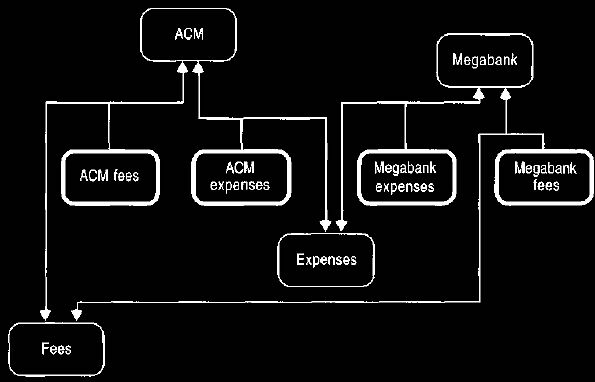
Figure 31. A typical fee/expense account structure.
The heavy bordered icons are detail accounts, summarized as shown by the arrows.
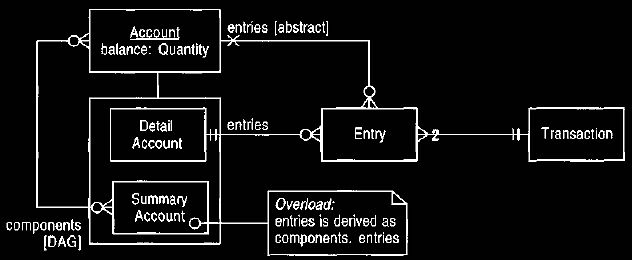
Figure 32. Allowing multiple summary accounts.
This diagram replaces the hierarchy of Figure 5 with a directed acyclic graph.
However, there is a small wrinkle that we must consider. What would occur if we had the account structure of
Figure 33? The account X sums over ACM and
fees, so the ACM fees account gets counted twice.
According to the model in Figure 32, we would still get a correct balance for X.
The balance is defined on a derived set of entries.
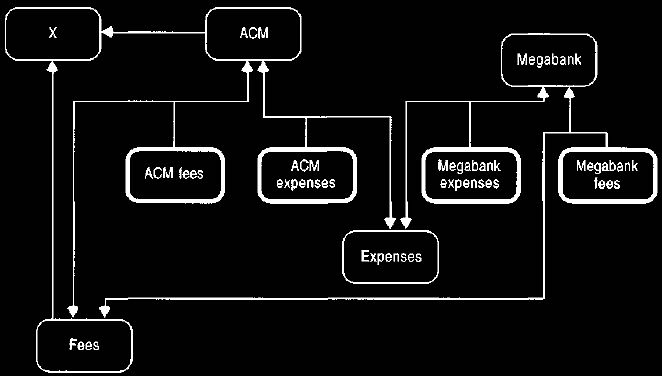
Figure 33. Account structure that highlights a problem.
If multiple summary accounts are used, someone could define a summary account
that has
overlapping detail accounts.
Sets do not
allow duplicates, so all the entries in ACM fees will only appear once in X,
thus
giving us a correct balance for X. However this balance will not be
equal to the
sums of the balances for fees and ACM, which might prove confusing. If this
confusion is a problem, we need a constraint on the components
relationship that
would not allow us to select components that had any overlap. This is a
reasonable
constraint since it is difficult to come up with an example
where such an
account
as X would be useful. Defining this kind of account is more likely to be the
product
of accident than design.
15.1 Using Memo Entries
The model works well at this level, but consider some further details. There may
be
a need to break down expenses in more detail. Tax regulations may
require us to
separate expenses for travel, lodging, and meals (for example, ACM-airfare,
ACM-lodging, Megabank-airfare, and so on). This could be done
by breaking each
expense account into detail accounts, but this could become difficult to manage
due to all the complex combination accounts.
It is worth exploring some other
options.
One option is to use entries into memo accounts. Thus $500 for a ticket to visit
ACM headquarters would result in depositing into both the ACM expenses
account and an airfare account. This method removes the need for
an ACM-airfare account but requires additional entries. A posting rule might
deal
with this to some extent, but we still need some statement about which expense
account is needed. This might be done by a special expense transaction creation
that takes parameters of from account, to account, and expense type memo
account.
Choosing whether the ACM expense account or the airfare account should be
a memo account depends on subsequent use of the account. If the ACM expense
account is being used to track the payment of invoices, while the airfare
account is
only being used for tax reporting, then the airfare account would make the
better
memo account. There's a certain amount of arbitrariness in choosing which
accounts hold the main stream of money, compared to those working with memo
accounts.
15.2 Derived Accounts
A different approach is to use a derived account, as in Figure 34. In this
case the
entries are specified by providing the derived account with a filter,
which selects matching entries. To work, the derived account needs
something on which to base its derivation. A sub-type of entry that supports an
expense category would do nicely, and then an account where the membership test
is expense category = airfare would create the desired information.
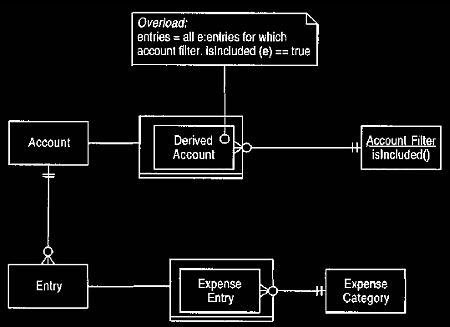
Figure 34. Introducing derived accounts.
We might consider taking this approach further. Why not abandon using
accounts altogether and just have something like Figure 35? We can then work
out what is going on just by queries on expense.

Figure 35. Expenses defined to abandon the accounting model.
A derived account can still allow us to use all the reporting behavior, but we
lose the
tracking behavior.
This question helps define why accounts are useful and why derived accounts
are valuable. Accounts work best within relatively static structures where
complex movements of assets need to be tracked. If the movements are simple,
such as just assigning an expense to airfare, then accounts are not really
needed.
However, consider the situation where we visit both Megabank and ACM in one
trip and charge two-thirds of the airfare to one and one-third to the other.
This is
the kind of multi-legged transaction that accounts handle well. However, the
model in Figure 35 has a real problem with this. How do we split a simple
payment up in this way? Note that the model in Figure 35 has another problem:
It does not say where the money comes from. We could add a credit card
association
to it, but then expense looks very similar to a two-legged transaction.
Using attributes for derived accounts is effective when the account structure
is not very static. If there are many possible cuts of information, then the
derived
account allows these to be computed easily using the same reporting facilities
that accounts have. However, they only have the reporting facilities. Derived
accounts cannot be posted to and thus cannot be used to track the ebb and flow
of
assets.
So whenever we are trying to represent an aspect of an entry, we have a
choice between an attribute of the entry or a new account level. The decision is
based on what part of the account behavior you need. If it is simply the
reporting
side, we can use an attribute and derive an account when it's needed.
Otherwise,
a
new level of accounts is required.
Recommendations
We can recommend a couple of other sources for information on accounts that will
give a different perspective to that presented in this analysis.
Hay has a
section
dedicated to accounting. His basic concepts of accounts and transactions is very
much the same as ours, although he does not present
anything on posting rules.
He goes into much more depth on the account types that are present in
corporations. He also discusses the common transactions
that are used in
corporations and how they fit into this accounting model. He also presents a
knowledge level for these account and transaction types.
There has been a lot of work at the University of Illinois at Urbana-Champaign
on developing an accounting framework. This takes a
very different approach
to Hay and myself. It starts with treating the
information
on an invoice (for example) as a high-level "transaction" against a high-level
account.
This "transaction" can then be broken down to lower-level
"transactions"
against lower-level accounts. They use the word transaction very differently
than
we do: They do not follow the principle of conservation. A high-level
"transaction"
might be an invoice with all its line items. The framework concentrates on
breaking this down into lower-level "transactions," such as the line items
themselves. Thus the framework is designed to break down a cluster of entries
into its component entries, rather than our approach of a network of accounts and
transfers between them.
See also:
Using the
Accounting Models
|